
Sports RAG.
Transforming Rulebook Knowledge with AI
Engineering Philosophy
Governance is the Guardrail
In a regulatory environment, "hallucinations" are liabilities. We architected the system to prioritize grounding over creativity—if the model cannot cite the specific rule article, it refuses to answer.
Context is the Query
Players describe messy, real-world scenarios; the rulebook uses rigid, legalistic terminology. The architecture had to bridge this semantic gap, translating "user slang" into "governance logic."
Evaluation is Engineering
Building the pipeline is easy; proving it works is hard. We established a rigorous "Ground Truth" framework, treating evaluation metrics as first-class citizens in the development lifecycle.
Project Overview
Industry
Sports Governance
Team
Data Engineering & Domain Experts
Role
Data Engineer, Architect
Context
The rulebook is not just a document; it is the law of the game. But as the sport expanded globally, the governing body faced a crushing operational bottleneck: **27,000+ annual inquiries** from players seeking clarification on complex scenarios.
My Role & Impact
Insight
Insight

Solution
A RAG-Based Knowledge Engine: Combining vectorized rulebooks with 10,000+ historical expert conversations.
Semantic Search Layer: A retrieval system capable of understanding the *intent* of a question, not just matching words.
Cited Evidence: A frontend that displays the generated answer alongside the specific rule extracts used to form the opinion.
Process & Execution
Discovery & Ecosystem Mapping
Analyzed the anatomy of 27,000 annual inquiries. We mapped the "question patterns" against the rulebook hierarchy to understand where the gaps in understanding were occurring.
Architecting the Pipeline
Designed a secure data flow: User Input → PII Redaction → Semantic Retrieval (Rules + History) → Context Injection → LLM Generation. This ensured data privacy while leveraging the full power of the organization's knowledge.
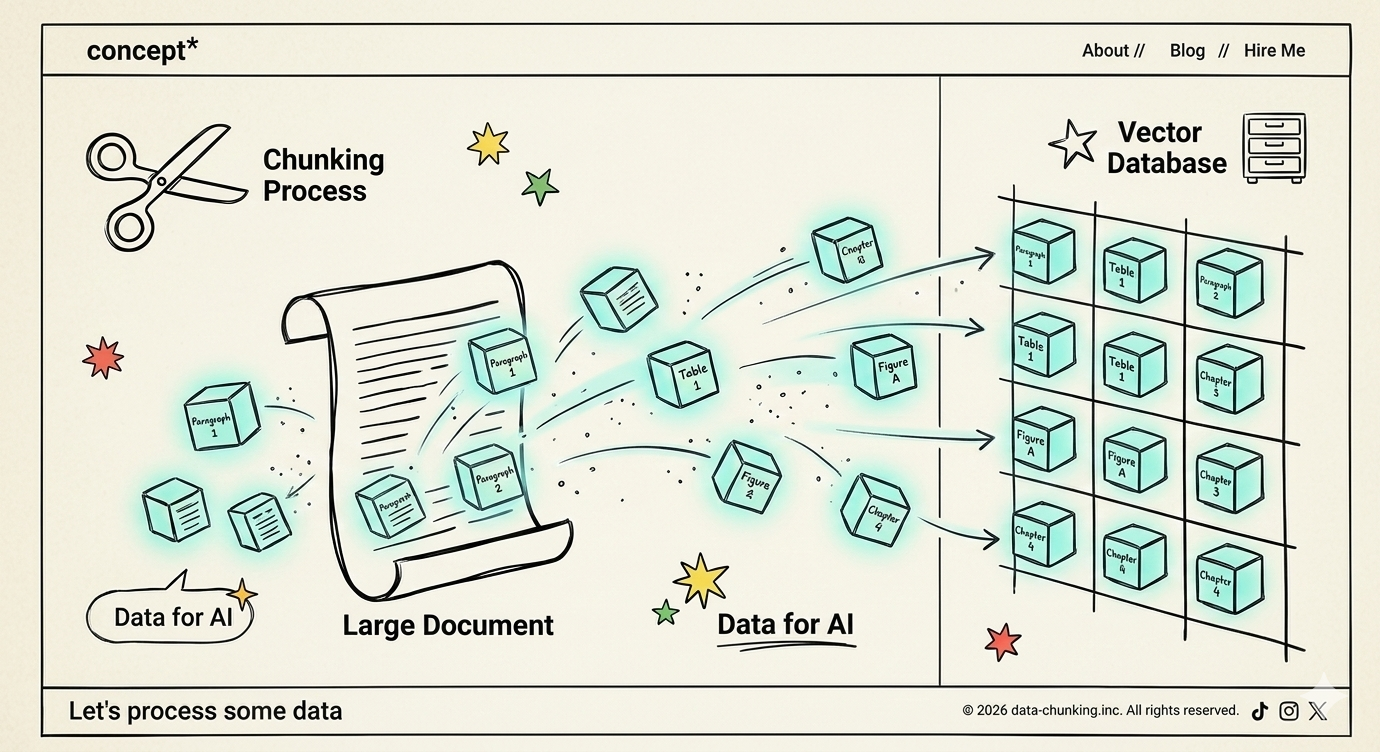
Vectorization & Segmentation
We discovered that ingesting the rulebook as a whole failed. We shifted to a "chunking" strategy, treating individual articles and email threads as discrete semantic units, significantly boosting retrieval precision.
The "Truth Loop" (Evaluation)
We didn't launch on faith. We built a validation set of 30 complex "edge case" questions and measured the model's output against answers written by the Chief Rules Official. ---
Learnings
Granularity Drives Accuracy
Breaking down the "monolith" of data into smaller, semantic chunks was the turning point for accuracy. The machine needs distinct concepts, not long chapters.
Hybrid Knowledge Bases
The Rulebook provided the "Theory," but the Historical Emails provided the "Practice." Combining them allowed the AI to handle edge cases that the rules technically covered but didn't explicitly describe.
From Chatbot to Infrastructure
This project wasn't just about building a chat interface; it was about turning a complex, static ecosystem into a queryable API that can power future public-facing tools and referee training modules.